

핸즈 온 머신러닝 (Hands-On Machine Learning with Scikit-Learn & TensorFlow) / 오렐리앙 제론 지음 , 박해선 옮김
을 읽고, 추후 기억을 되살릴 수 있게끔 나만의 방법으로 내용을 리뷰한다. 따라서 리뷰의 내용 별 비중이 주관적일 수 있다.
챕터 6. 결정 트리
Decision Tree는 분류와 회귀, 다중 출력 모두 가능한 다재다능한 머신러닝 알고리즘이다.
6.1 결정 트리 학습과 시각화
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
sklearn.tree.DecisionTreeClassifier — scikit-learn 0.22.1 documentation
scikit-learn.org
https://scikit-learn.org/stable/modules/generated/sklearn.tree.export_graphviz.html
sklearn.tree.export_graphviz — scikit-learn 0.22.1 documentation
scikit-learn.org
위의 두 함수를 이용하여 그래프를 정의하고, 시각화 할 수 있다.
6.2 예측하기
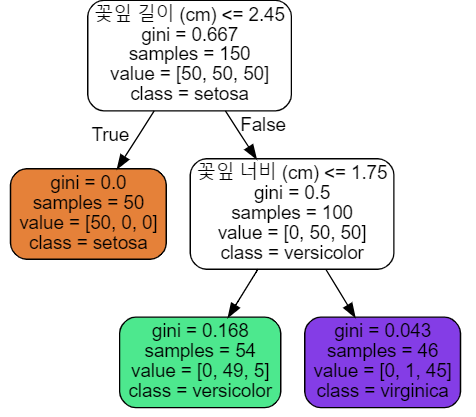
트리는 root node에서 시작하여, 각각의 node에 정해져 있는 규칙에 따라 가지를 따라 내려가고, 더 이상 child node가 없는 leaf node에 도착하면 해당 leaf에 적혀 있는 class로 분류가 된다. 각각의 노드에는 불순도가 적혀있는데, 위 tree의 경우 gini method를 사용하고 있다. 기본적으로 각각의 노드에서는 하나의 특성에 대해서 기준을 나누므로 그래프에 표시해보면 수직 혹은 수평인 기준선들이 존재한다.
6.3 클래스 확률 추정
leaf class에 도달하였을 때 해당 leaf의 클래스 비율을 본다면 확률 추정도 가능하다. sklearn 의 decision tree에서는 predict_proba 함수를 사용하여 알 수 있다.
6.4 CART 훈련 알고리즘
트리를 만들기 위해서 사이킷 런은 CART (Classification And Regression Tree) 알고리즘을 사용한다. training data를 하나의 특성, 하나의 임곗값을 이용해 두 서브셋으로 나눈다. 이 때 특성과 임곗값은 두 서브셋의 불순도에 가중치를 곱해 최소가 되도록 하는 값으로 정한다. 기본적으로는 모든 조합을 해보아야 그 순간 최적의 분할을 알 수 있다. 트리가 너무 복잡해지는 것을 막기 위해 max_depth, min_smaples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes 등을 사용하여 규제를 둘 수 있다. 자세한 것은 위에 언급한 document에서 확인할 수 있다.
또한 CART 알고리즘은 각 순간에서 최적의 분할을 찾기 때문에 Greedy Algorithm 이며 완전히 최적인 나무를 찾는 것은 아니지만 매우 효율적이다.
6.5 계산 복잡도
CART 알고리즘에서 각 노드를 분할할 때에 O(n m') 의 시간이 필요하다. 경우에 따라 다르지만 결정트리는 주로 O(log m)의 층으로 구성되어있다. 각 층에는 총 O(m) 개의 데이터가 있다고 할 수 있으므로 총 시간 복잡도는 O(n m log m) 이다.
정확히는, T(m) = T(a) + T(m-a) + O(n m) 의 함수를 계산하면 구할 수 있다. a가 항상 1이라면 T(m) = O(n m^2) 이지만, a가 대략 m/2라고 가정하면 T(m) = O(n m log m)이 된다.
6.6 지니 불순도 또는 엔트로피?
불순도를 측정하는 대표적인 두 가지 방법은 지니 불순도와 엔트로피이다. 지니 불순도는 1 - sum( p(i)^2 ) 이고, 엔트로피는 - sum ( p(i) log (p(i)) ) 이다. 지니 불순도는 빈도 높은 클래스를 고립시키는 경향이 있고 엔트로피는 조금 더 균형 잡힌 트리를 만드는 경향이 있지만, 거의 비슷하다.
6.7 규제 매개변수
과대적합을 피하기 위해 학습할 때 결정 트리의 자유도를 규제를 통해 제한할 필요가 있다.
max_depth : 최대 깊이
min_samples_split : 분할되기 위해 노드가 가져야 하는 최소 샘플 수
min_samples_leaf : 리프 노드가 가져야 하는 최소 샘플 수
min_weight_fraction_leaf : 피트 노드가 가져야 하는 전체 샘플 수에서의 비율
max_leaf_nodes : 리프 노드의 최대 수
max_features : 분할에 사용할 특성의 최대 수
등이 있다. 혹은, 트리를 다 만든 후 통계적으로 검정하여 pruning 하는 방법도 존재한다.
6.8 회귀
결정 트리는 회귀에도 사용할 수 있다.
https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeRegressor.html
sklearn.tree.DecisionTreeRegressor — scikit-learn 0.22.1 documentation
scikit-learn.org
이는 분류와 매우 비슷하지만, leaf node에서 class 대신 값을 유추하며 불순도 최소화 대신 MSE를 최소화 한다. 마찬가지로 규제가 필요하다.
6.9 불안정성
트리는 사용하기 편하고 여러 용도로 사용할 수 있지만, 경계를 항상 계단모양으로 만들기 때문에 회전된 데이터에 매우 불안하며, 데이터의 작은 변화에 민감하다는 단점이 있다. 해결법은 PCA를 하여 특성을 합쳐주거나 RandomForest를 사용하는 것이다.
'개발 인생 > ML' 카테고리의 다른 글
| 핸즈 온 머신러닝 :: 8. 차원 축소 (0) | 2020.01.18 |
|---|---|
| 핸즈 온 머신러닝 :: 7. 앙상블 학습과 랜덤 포레스트 (1) | 2020.01.17 |
| 핸즈 온 머신러닝 :: 5. 서포트 벡터 머신 (0) | 2020.01.16 |
| 핸즈 온 머신러닝 :: 4. 모델 훈련 (0) | 2020.01.16 |
| 핸즈 온 머신러닝 :: 3. 분류 (0) | 2020.01.16 |