

핸즈 온 머신러닝 (Hands-On Machine Learning with Scikit-Learn & TensorFlow) / 오렐리앙 제론 지음 , 박해선 옮김
을 읽고, 추후 기억을 되살릴 수 있게끔 나만의 방법으로 내용을 리뷰한다. 따라서 리뷰의 내용 별 비중이 주관적일 수 있다.
챕터 4. 모델 훈련
모델이 어떻게 작동하는지 잘 이해하면 모델 및 알고리즘 설정, 하이퍼 파라미터 변경을 적절하고 빠르게 할 수 있다.
4.1 선형 회귀
선형 회귀는 특성들의 선형 함수로 함수 값을 예측하며, 주로 RMSE를 최소화하는 선형 파라미터를 학습한다.
4.1.1 정규방정식
선형 회귀는 수학적으로 RMSE를 최소화하는 파라미터를 계산을 통해 구할 수 있다.
4.1.2 계산 복잡도
정규 방정식을 통해 파라미터를 구할경우 계산 복잡도는 O(n^2.4) 에서 O(n^3) 정도가 된다. 다행히도 샘플 수에는 선형적으로 증가한다. (O(m))
4.2 경사 하강법
Gradient Descent는 여러 종류의 문제에서 최적의 해법을 찾을 수 있는 매우 일반적인 최적화 알고리즘이다. 핵심 아이디어는 Cost Function을 최소화하기위해 함수를 미분하여 파라미터를 조정하는 것이다. 이 때에 learning late가 중요한데 너무 작거나 크면 안된다. 또한 Gradient Descent는 해를 local minimum으로 수렴하게 만드는 경우가 있는데 함수가 Convex일 경우 local minimum은 항상 global minimum이다.
경사 하강법을 사용할 때에는 값들을 정규화해 주는 것이 훨씬 효율적이다.
4.2.1 배치 경사 하강법
MSE 값을 각각의 파라미터로 미분한 후, 해당 방향으로 learning late를 곱하여 감소시켜주는 것이 배치 경사 하강법이다. 이 때, 모든 train data에 해당하는 MSE 값을 최소화하게 된다. learning late를 적당히 조절하여 학습 하는 것이 중요하다. 반복 횟수는 변화 값이 어느 수준 이하가 될 때까지 반복하는 것이 좋다.
4.2.2 확률적 경사 하강법
배치 경사 하강법에서는 모든 데이터를 사용하여 그래디언트를 계산하기 때문에 계산량이 많고 속도가 느리다. 반대로 확률적 경사 하강법은 매 스텝에서 딱 한개의 샘플을 무작위로 선택하여 그래디언트를 계산하는 것이다. 이는 계산을 매우 빠르게 만들어 준다. 하지만 학습을 반복한다면 마지막에 수렴하지 않는 모습을 보일 수 있으므로, 학습률을 점점 줄이는 것이 좋은 해결법 중 하나이다. 이를 학습 스케쥴링이라고 한다.
4.2.3 미니배치 경사 하강법
미니배치 경사 하강법은 하나의 샘플을 기반으로 그래디언트를 계산하는 것이 아니라 미니배치라 부르는 샘플 세트에 대해 계산하는 것이다.
4.3 다항 회귀
데이터가 선형보다 복잡한 형태여도 선형 회귀를 사용할 수 있는데, 각 특성의 거듭 제곱을 특성으로 포함하여 선형 회귀를 학습시키면 된다. 직접 특성을 추가하여도 되지만 sklearn의 PolynomialFeatures를 사용할 수 있다.
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.PolynomialFeatures.html
sklearn.preprocessing.PolynomialFeatures — scikit-learn 0.22.1 documentation
scikit-learn.org
4.4 학습 곡선
고차 다항 회귀를 적용하면 기존의 선형 회귀 보다 훨씬 더 훈련 데이터에 잘 맞추려 할 것이다. 하지만 이는 훈련데이터에 과대적합 되는 모델이다. 그렇다고 선형 회귀를 사용하면 과소적합이 된다. 따라서 적당한 차수의 다항 회귀를 사용하여야 하는데, 학습 곡선을 그려보면 도움이 될 것이다.
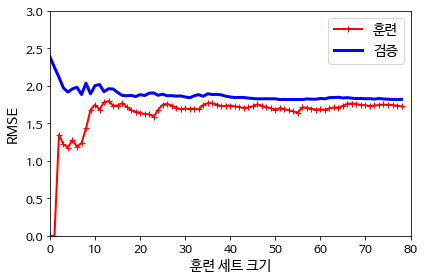
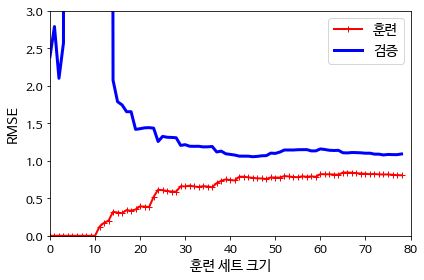
좌측은 과소적합의 학습 곡선이고 우측은 과대적합의 학습 곡선이다.
과소 적합의 경우 두 곡선이 높은 오차에서 평행하게 된다. 훈련은 잘 했지만 모델 자체가 오차를 줄일 수 없기 때문이다. 과대적합의 경우 훈련 데이터의 오차가 작아지는데 검증 데이터의 오차와 차이가 있다.
오차는 세 가지 다른 종류의 오차의 합으로 표현된다.
- 편향 : 편향은 잘못된 가정에 의한 것으로 훈련 데이터에 과소 적합되기 쉽다.
- 분산 : 분산은 데이터의 작은 변동에 모델이 민감하게 반응하기 때문에 일어나는 것으로 과대적합 되기 쉽다.
- 줄일 수 없는 오차 : 줄일 수 없는 오차는 데이터 자체의 노이즈 때문에 발생하는 것으로 노이즈를 제거하는게 유일한 해결법이다.
4.5 규제가 있는 선형 모델
모델에 제한을 두어 규제하면 과대적합을 피할 수 있다.
4.5.1 릿지 회귀
훈련하는 동안 모델의 파라미터 크기에 제한을 두면 가중치가 작게 유지되도록 노력하여 과대적합을 피할 수 있다. 릿지 회귀는 비용함수에 파라미터 제곱에 비례한 값을 추가하는 것이다.
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html
sklearn.linear_model.Ridge — scikit-learn 0.22.1 documentation
scikit-learn.org
위 모델을 이용하여 학습하거나, SGD Classifier에서 'l2' penalty를 추가하면 된다.
4.5.2 라쏘 회귀
라쏘 회귀는 릿지 회귀와 비슷하지만 파라미터 제곱이 아닌 파라미터 절댓값에 비례한 비용을 추가하는 것이다. 릿지 회귀는 가중치가 원점에 가까이 가려고 한다면 라쏘 회귀는 필요없는 가중치를 완전히 제거하려는 특성을 가진다. 특정 곡선이 원에 접하는 점을 찾는 경우와, 다이아몬드에 접하는 점을 찾는 경우를 비교해보면 될 것이다.
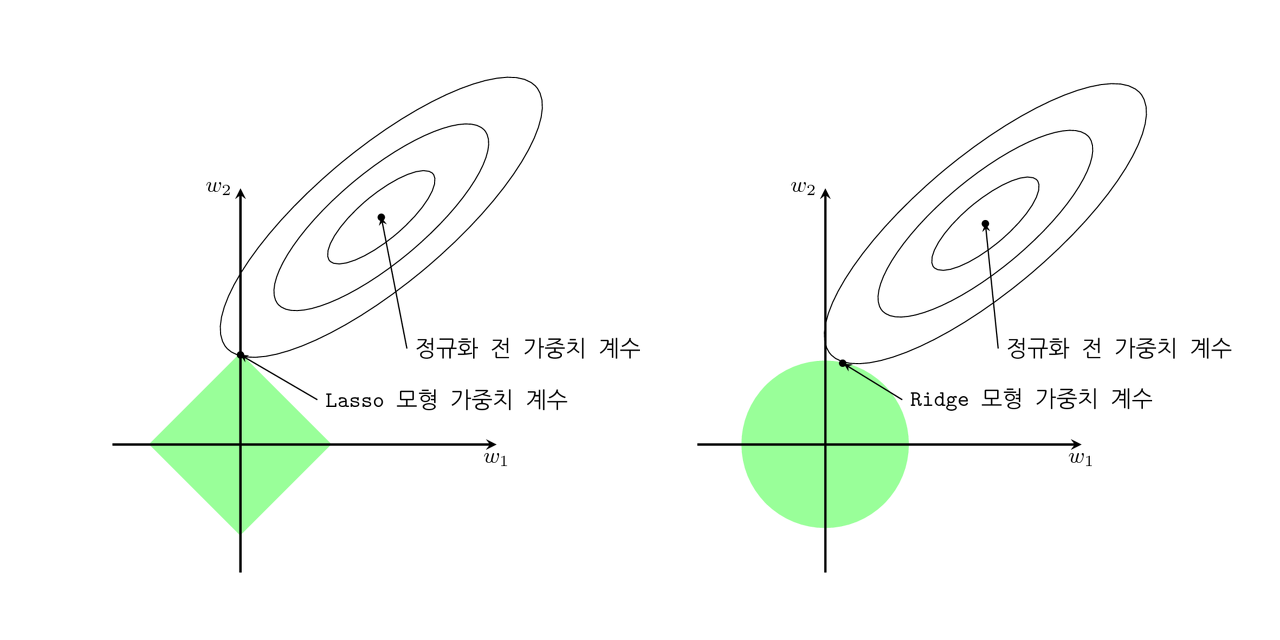
라쏘 회귀의 그래디언트는 0에서 미분 불가능 하므로 0일때 미분값이 0으로 주어지는 서브그래디언트 벡터를 사용하면 된다.
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Lasso.html
sklearn.linear_model.Lasso — scikit-learn 0.22.1 documentation
scikit-learn.org
마찬가지로 'l1' penalty를 추가한 SGD Classifier를 사용할 수 있다.
4.5.3 엘라스틱넷
엘라스틱 넷은 릿지 회귀와 라쏘 회귀를 절충한 모델으로, 비용함수의 두 가중치를 특정 비율로 섞으면 된다. 라쏘 회귀는 가끔 문제를 일으키므로 이 경우에 엘라스틱넷을 사용하면 될 것이다.
4.5.4 조기 종료
반복 횟수에 따라 훈련 세트의 RMSE는 줄어들 가능성이 높지만 검증 세트에 대한 RMSE는 과대적합시 증가할 가능성이 높으므로 검증 세트에 대한 RMSE가 다시 증가하려는 추세가 보일 때 학습을 중지하는 것이 좋다. 이를 early stopping 이라고 한다.
4.6 로지스틱 회귀
회귀 알고리즘을 사용하여 분류 모델을 만드는 것을 Logistic Regression 이라고 한다.
4.6.1 확률 추정
선형 회귀의 값이 주어졌다면, 이를 sigmoid function에 대입하여 0과 1사이의 확률로 변환하는 것을 로지스틱 회귀 모델이라고 한다. 이 값이 0.5 (혹은 다른 기준) 보다 크다면 분류 함수에서는 양성 클래스로 예측하면 된다.
4.6.2 훈련과 비용 함수
따라서 양성 샘플의 경우 logit의 값이 크고, 음성 샘플의 경우 logit의 값이 작도록 모델을 학습해야 한다.
비용함수는 y=1일 때 -log(p), y=0일 때 -log(1-p)인 함수를 사용한다. 이를 하나의 식으로 표현하려면 - y log (p) - (1-y) log (1-p) 와 같이 표기하면 된다. 이 함수는 미분 가능하므로 경사 하강법 알고리즘을 적용하여 학습할 수 있다.
4.6.3 결정 경계
로지스틱 회귀를 이용하여 추측된 양성 확률이 0.5보다 크다면 양성 확률이 음성 확률보다 크다는 뜻이므로 양성 클래스로 예측하게 된다. 로지스틱 회귀도 선형 회귀를 기반으로 작동하기 때문에 그래프에서의 경계가 선형으로 나타난다. 로지스텍 회귀 모델도 패널티를 적용할 수 있다.
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
sklearn.linear_model.LogisticRegression — scikit-learn 0.22.1 documentation
scikit-learn.org
4.6.4 소프트맥스 회귀
여러 개의 binary classifier를 사용하지 않고 하나의 회귀 모델으로 다중 클래스를 분류할 수 있다. 이를 Softmax Regression 혹은 Multinomial Logistic Regression 이라고 한다.
각 클래스 k에 대해 로지스틱 회귀 모델을 학습 한 후, 각각의 회귀 값을 지수화 하여 정규화 하면 된다. 즉 식으로는
exp(s_k(x)) / sum (exp(s_k(x)) 가 된다. 이 값들의 합은 1이 되므로 각각을 확률로 볼 수 있으며, 가장 큰 확률을 가지는 클래스로 예측하면 된다.
이 모델의 경우 새로운 비용함수를 적용하여야 하는데 주로 cross entropy function을 사용한다.
'개발 인생 > ML' 카테고리의 다른 글
| 핸즈 온 머신러닝 :: 6. 결정 트리 (0) | 2020.01.17 |
|---|---|
| 핸즈 온 머신러닝 :: 5. 서포트 벡터 머신 (0) | 2020.01.16 |
| 핸즈 온 머신러닝 :: 3. 분류 (0) | 2020.01.16 |
| 핸즈 온 머신러닝 :: 2. 머신러닝 프로젝트 처음부터 끝까지 (0) | 2020.01.15 |
| 핸즈 온 머신러닝 :: 1. 한눈에 보는 머신 러닝 (0) | 2020.01.13 |