
파이썬 넘파이의 r_, c_ 에 대해 설명하고자 한다.
데이터 전처리 과정에서 여러 행렬을 column으로 이어 붙이기 위해 numpy.c_을 사용하곤 한다.
numpy.c_ 의 정확한 정의는 다음 document를 보면 알 수 있다.
https://docs.scipy.org/doc/numpy/reference/generated/numpy.c_.html
numpy.c_ — NumPy v1.17 Manual
Translates slice objects to concatenation along the second axis. This is short-hand for np.r_['-1,2,0', index expression], which is useful because of its common occurrence. In particular, arrays will be stacked along their last axis after being upgraded to
docs.scipy.org
numpy.c_은 numpy.r_에 ('-1,2,0') 인자를 추가한 것으로 정의되어있다.
따라서 정확한 정의를 알기 위해서는 r_의 document를 보아야 한다.
https://docs.scipy.org/doc/numpy/reference/generated/numpy.r_.html
numpy.r_ — NumPy v1.17 Manual
Parameters: Not a function, so takes no parameters
docs.scipy.org
r_의 사용법으로는 여러 가지가 있다.
예제 코드를 보며 알아보자.

numpy.r_은 함수 ( ) 를 이용하여 호출하는 것이 아니라 연산자 [ ] 를 이용하여야 한다.
가장 기본적인 사용법으로는 1차원 벡터들을 나열하여 행으로 붙이는 것이다.
위의 예제들은 문서에서 제시된 사용법이다.
If slice notation is used, the syntax start:stop:step is equivalent to np.arange(start, stop, step) inside of the brackets. However, if step is an imaginary number (i.e. 100j) then its integer portion is interpreted as a number-of-points desired and the start and stop are inclusive. In other words start:stop:stepj is interpreted as np.linspace(start, stop, step, endpoint=1) inside of the brackets. After expansion of slice notation, all comma separated sequences are concatenated together.
-1:1:6j 는 -1부터 1까지를 6개의 수로 slice한 벡터를 뜻한다.
이제 r_의 첫 인자로 string을 보낼 때의 사용법을 알아보자.
사실 이 부분을 이해하기가 어려워서 본 글을 작성하게 되었다.
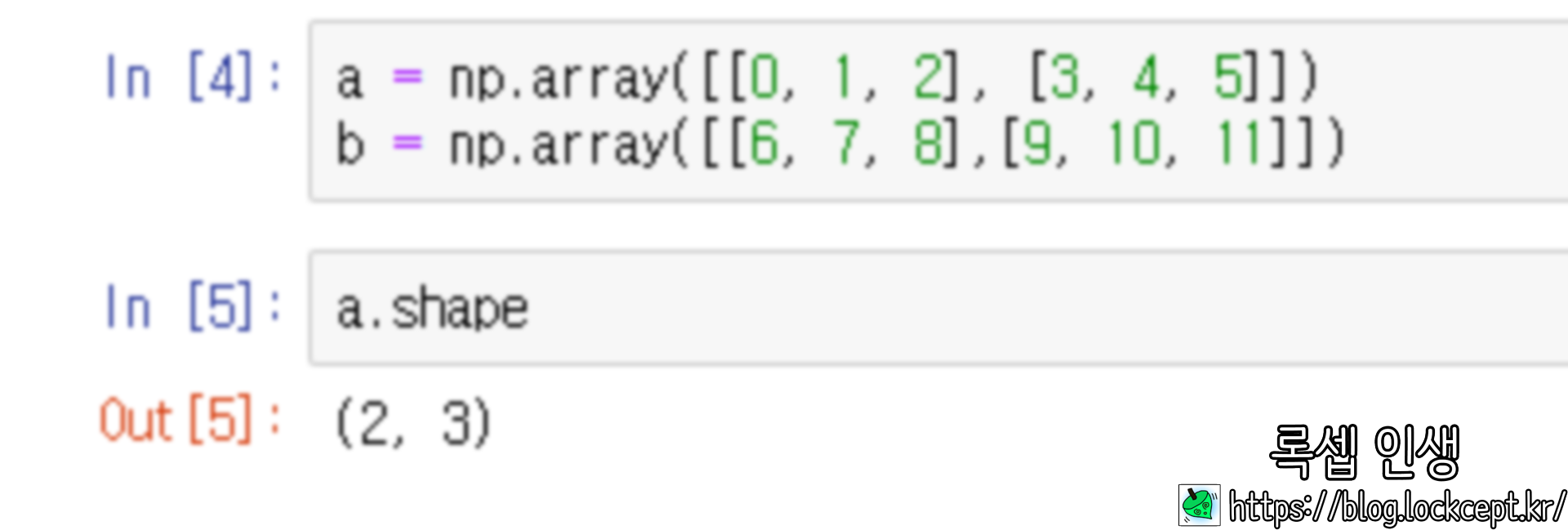
(2, 3) 크기의 두 numpy array를 선언하자.

string으로 최대 세 개까지의 정수 인자를 보낼 수 있는데, 가장 첫 번째 수는 concatenate 할 axis를 뜻한다.
axis 0 을 따라 합친다면 (4, 3)의 array가 될 것이며 axis 1을 따라 합친다면 (2, 6)의 array가 될 것이다.

두 번째 인자는 합칠 ndarray들을 확장할 dimension을 뜻한다.
예를 들어 위 예제의 경우 1차원 ndarray들이 인자로 들어왔지만, 2차원으로 확장한 후 합치겠다는 의미이다.
따라서 '0, 2'로 합칠경우 2차원 ndarray가 반환되며
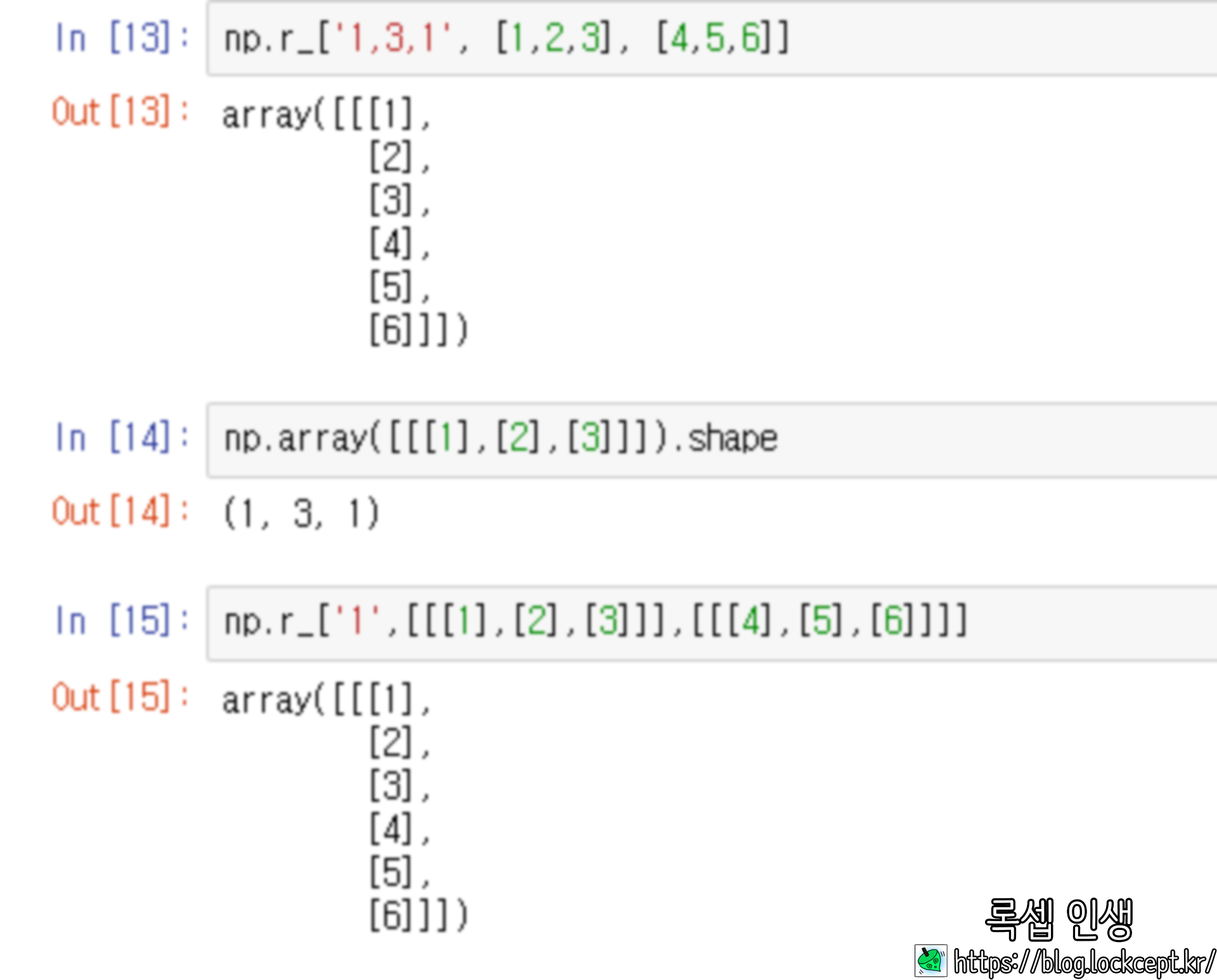
'1, 3'으로 합칠경우 3차원 ndarray가 반환된다.
두 경우의 concatenate axis가 다르다. 왜 저렇게 되는지 스스로 이해해 보고 넘어가자.
개인적으로 shape의 크기를 생각하며 이해하면 더 편하다. (아래의 경우 (1,1,3), (1,1,3) 에서 (1,2,3)이 됨)
세 번째 인자가 상당히 헷갈렸다.
두 번째 인자에 따라 행렬을 확장하는 과정에서 세 번째인자가 필요하다.
A string with three comma-separated integers allows specification of the axis to concatenate along, the minimum number of dimensions to force the entries to, and which axis should contain the start of the arrays which are less than the specified number of dimensions. In other words the third integer allows you to specify where the 1’s should be placed in the shape of the arrays that have their shapes upgraded. By default, they are placed in the front of the shape tuple. The third argument allows you to specify where the start of the array should be instead. Thus, a third argument of ‘0’ would place the 1’s at the end of the array shape. Negative integers specify where in the new shape tuple the last dimension of upgraded arrays should be placed, so the default is ‘-1’.
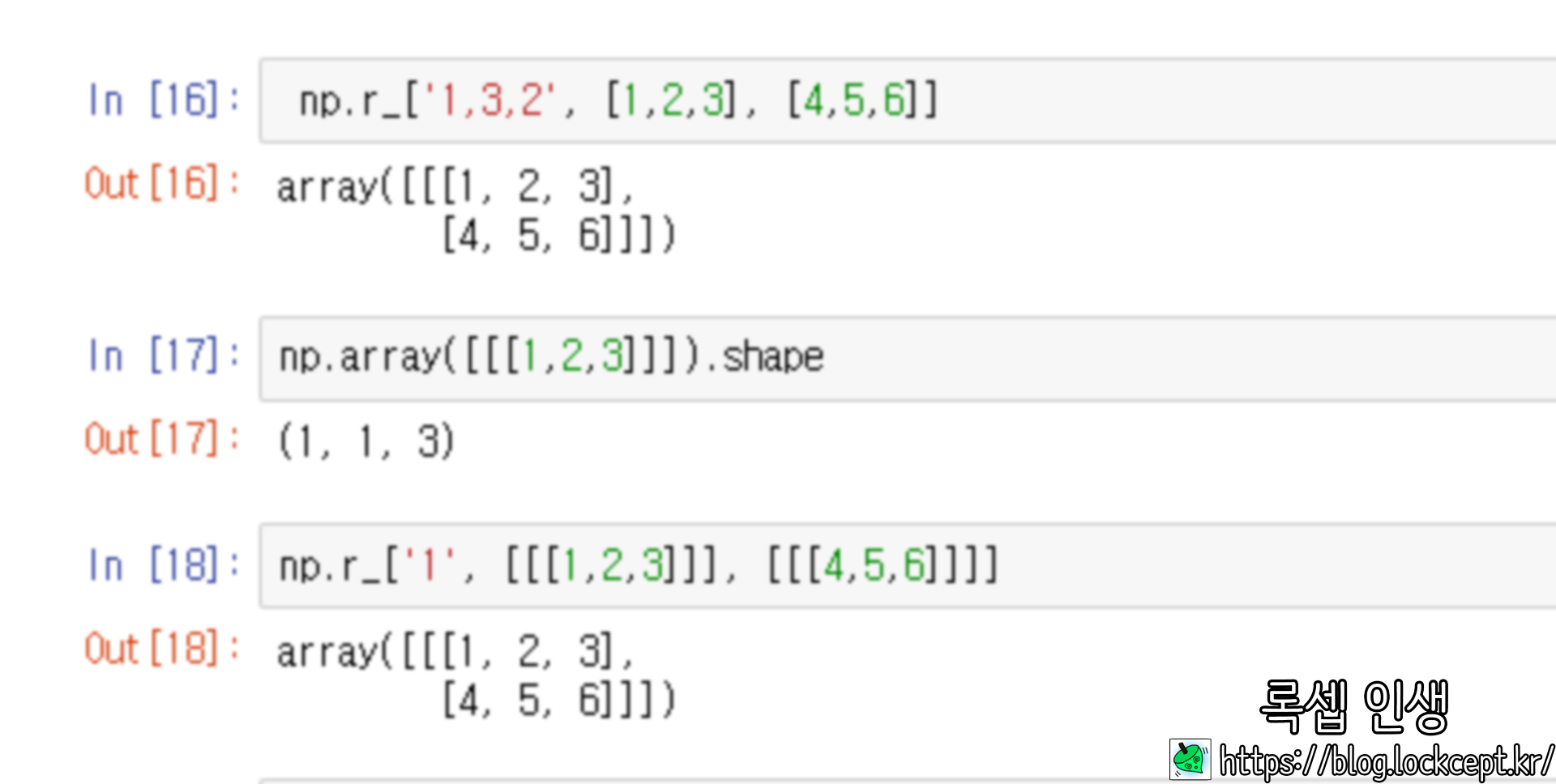
예를 들어 (3, )을 3차원으로 확장할 때에 (1, 1, 3)으로 확장할 지 (1, 3, 1)로 확장할지 (3, 1, 1)로 확장할 지 정해주는 인자이다.

0을 입력한다면 원래의 축이 0번째 축부터 적용되어 (3, 1, 1)로 확장 된다.
실제로 직접 (3, 1, 1)로 확장하여 대입해주면 같은 결과를 뱉는다.
같은 원리로 1을 입력한다면 (1, 3, 1)로 확장되어 적용된다.
2를 입력하는 경우도 마찬가지.
default 값은 -1로 가능한 가장 큰 수를 입력하는 것이다.
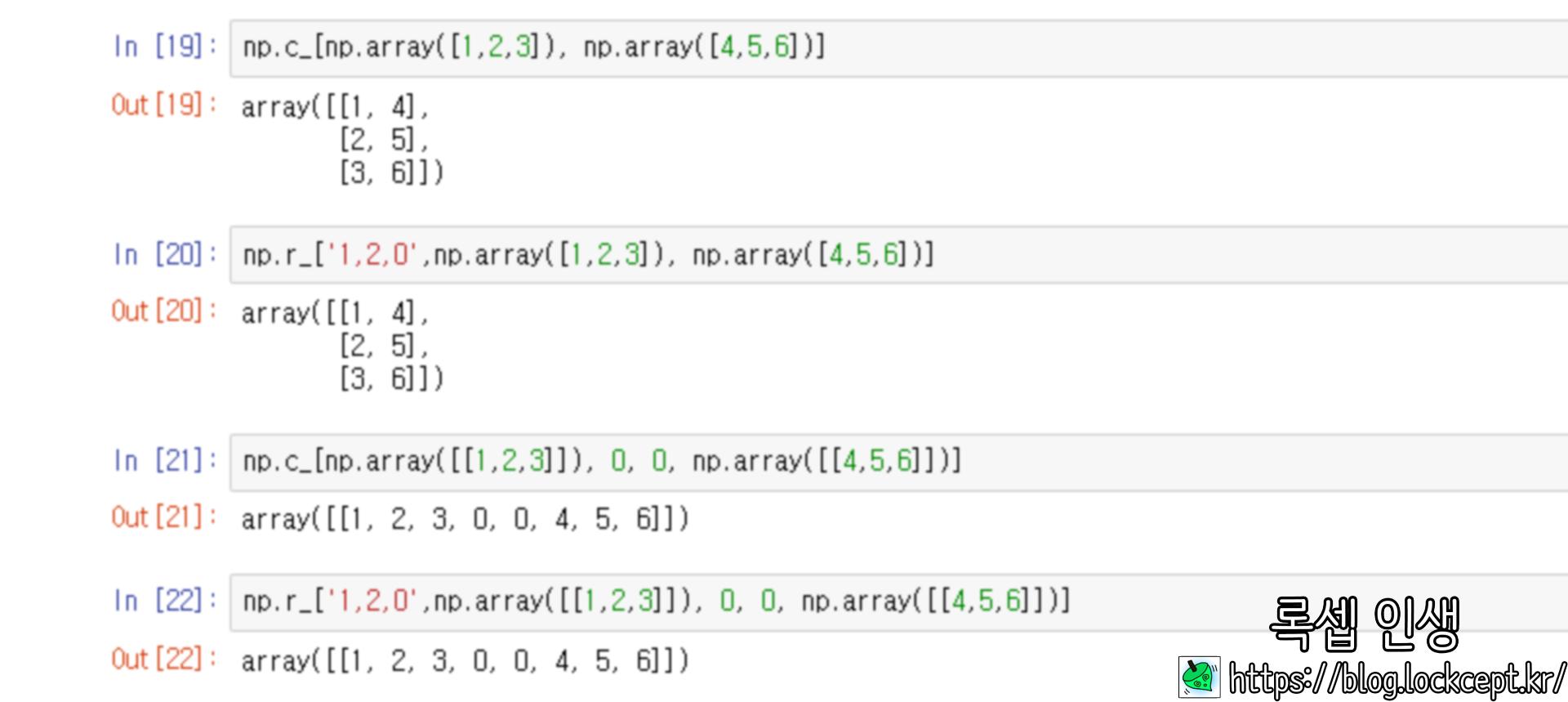
이제야 np.c_을 이해할 수 있게 되었다. '-1, 2, 0' 을 인자로 추가하는 것이므로
마지막 축을 따라 더한다 , 2차원으로 확장하여 더한다, 확장은 (n, )을 (n, 1)로 확장한다.
따라서 벡터를 열로 만들어 붙이는 연산이 되는 것이다.